https://www.acmicpc.net/problem/11658

자료구조
- 2차원 segment tree
사용 언어
- Python
시간 복잡도
- $O(m(logn)^2)$
풀이
포인트
- segment tree안에 또 다른 segment tree (2차원)을 구현하여 시간 복잡도를 $(logn)^2$로 맞춰야한다는 점
2차원 segment tree
이 문제는 2차원 배열에서 수를 변경하는 쿼리가 발생할 때, 이를 효율적으로 처리하면서 주어진 2차원 배열에 대한 합도 구해야하는 문제이다. 우선 segment tree을 사용하지 않고 단순하게 문제를 푸는 경우를 생각해보자. 2차원 배열에서 수의 변경이 일어나는 쿼리를 처리하는데에는 $O(1)$의 시간이, 배열의 합을 구하는데에는 $O(N^2)$의 시간이 소요된다. 이러한 연산을 총 $M$번 해야하므로, 총 시간 복잡도는 $O(MN^2)$이고 이는 TIL이 발생할 것이다.
따라서 자료구조를 사용하여 효율적으로 문제를 해결해야한다. 이 문제 같은 경우에는, segment tree안에 segment tree을 집어넣는, 2차원 segment tree 자료구조를 구현하여 해결할 수 있다. 여기서 첫 번째로 등장하는 segment tree는 열에 대한 tree, 그 안에 구현되는 segment tree는 행에 대한 tree이다. 문제의 2차원 배열 예시에서 (1,1) ~ (2,2)의 부분합을 구하는 예시를 통해 구체적으로 살펴보자.
열에 대한 segment tree (첫 번째 segment tree)
문제의 2차원 배열은 4 * 4 배열이므로 열 개수는 4개이다. 이 4개의 열에 대한 정보를 담는 segment tree을 먼저 만들어준다. 1차원 segment tree 문제에서는 각 tree의 node 값이 부분 합이거나 곱 등, 특정 값을 가졌다. 이 문제에서는 특정 값이 아니라, 행에 대한 segment tree 자체가 일종의 값 개념으로 들어가는 것이다. 4개의 열에 대한 정보를 담고 있는 segment tree는 아래와 같다.
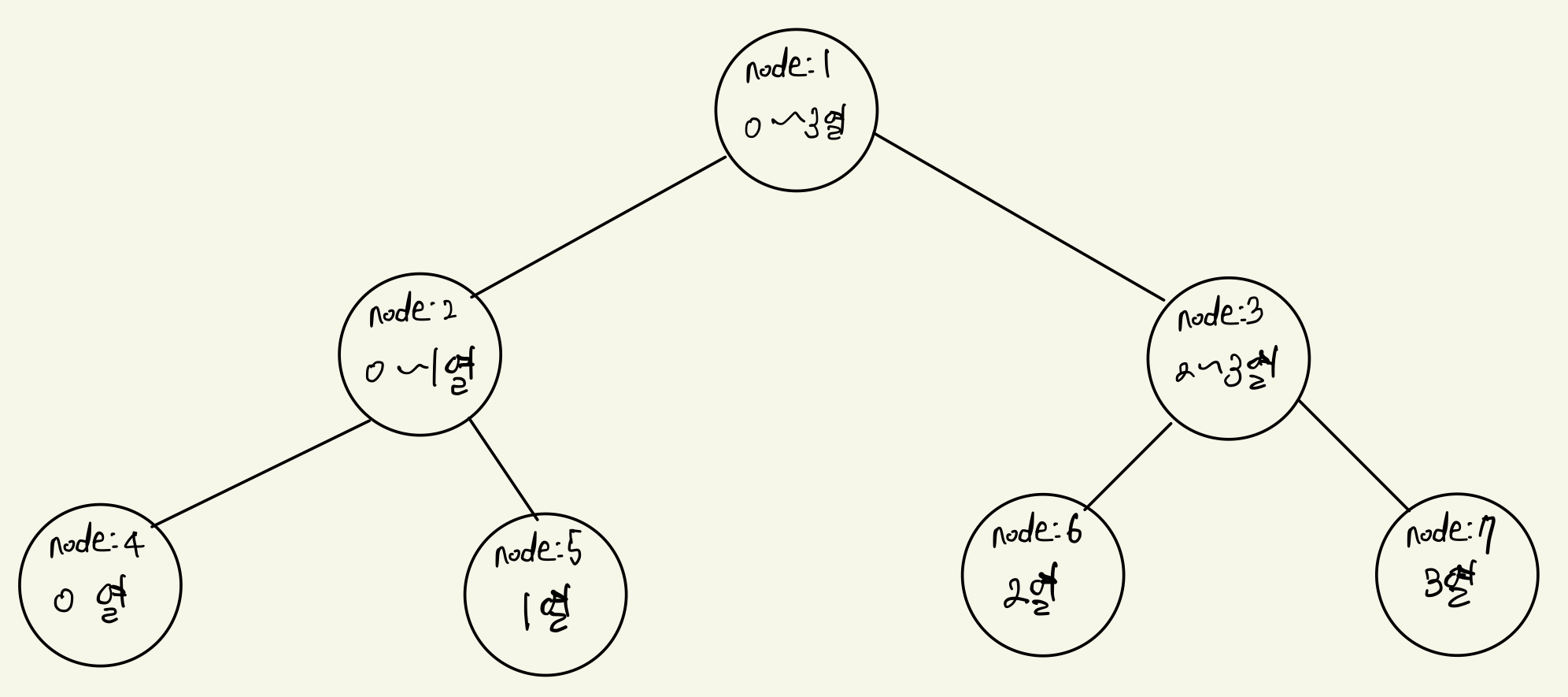
여기서 조금 이해하기 힘들 수도 있는 것이 node 값으로 행에 대한 segment tree가 들어간다는 것이다. 1번 노드의 값으로 들어가는 segment tree에 대해서 생각해보자.
1번 노드는 0열~3열에 대한 정보를 담고 있다. 여기서 0행에 대한 부분합만 취하고 싶다면 (0,0) ~ (0,3)의 부분합을 알고 싶은 것이다. 따라서 2차원 배열을 아래와 같이 1차원 배열로 바꿔서 생각해본다.
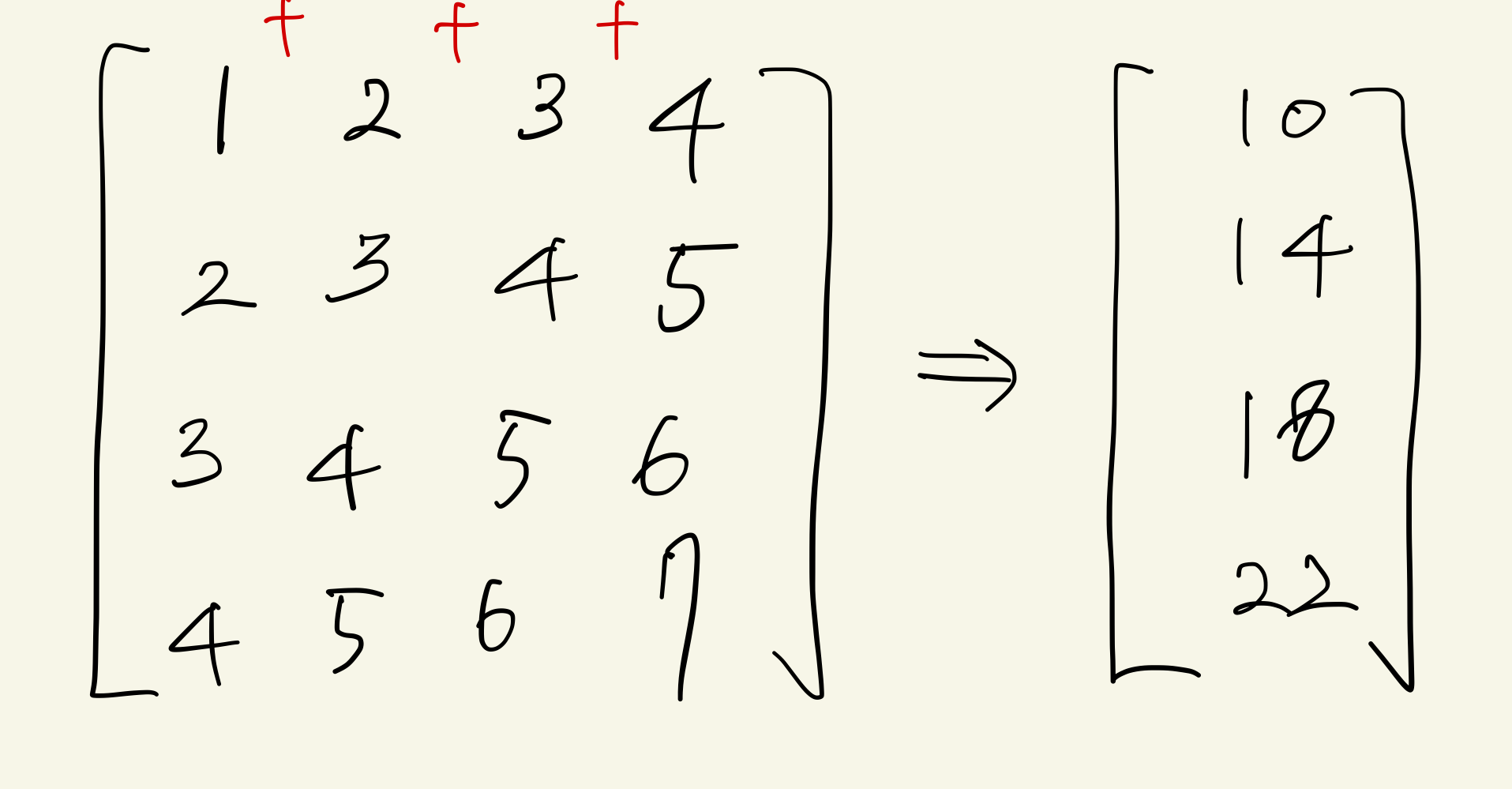
바뀐 1차원 배열은 4개의 원소로 구성되어 있고, 각 원소는 각 행에 대한 부분합을 의미한다. 바로 이 1차원 배열에서 또 segment tree을 만들어서 1번 노드 값으로 넣는 것이다. 1번 노드의 값인, segment tree을 그림으로 표현하면 아래와 같다.
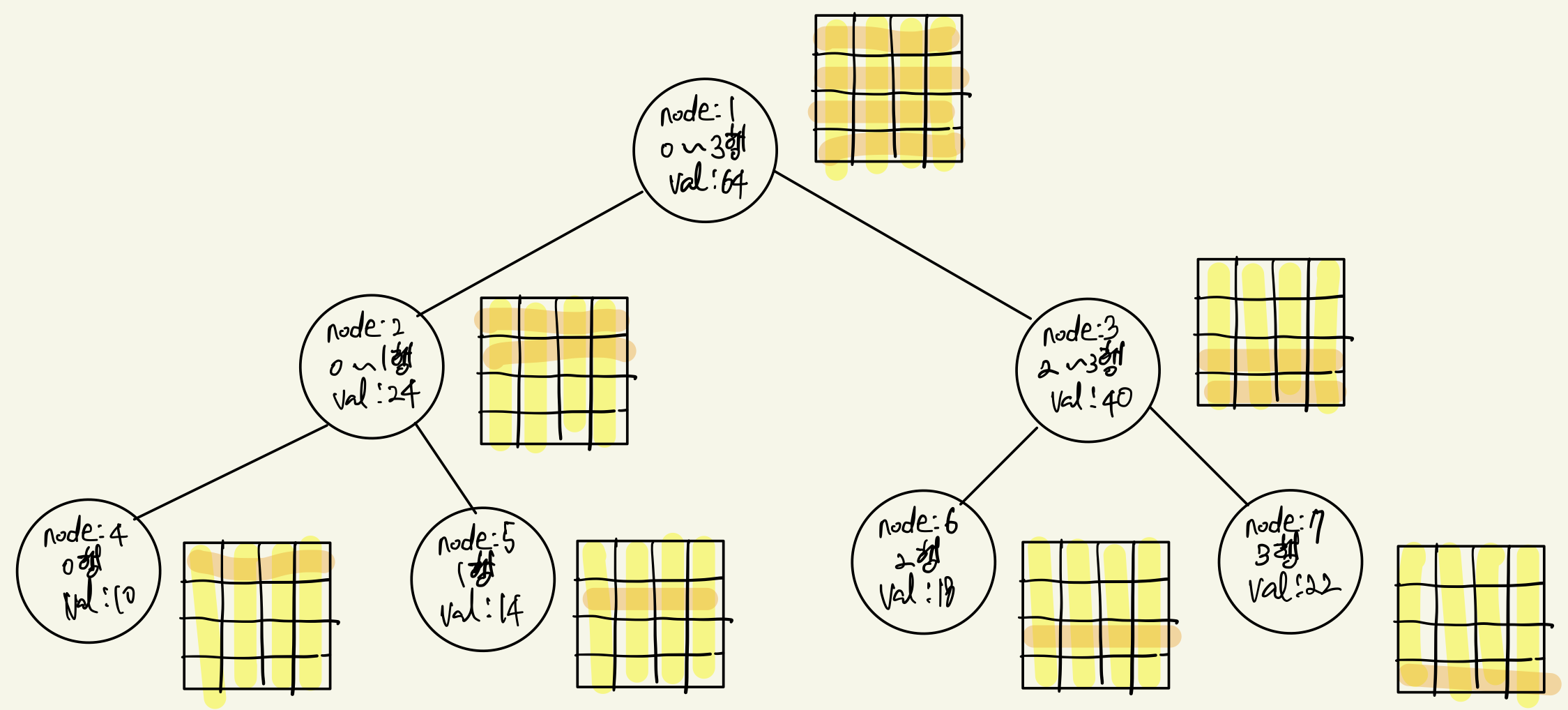
행에 대한 segment tree을 이해하는 것은 어렵지 않다. 먼저 위 segment tree는 열에 대한 segment tree 기준으로 1번 노드의 값임을 기억하자. 다시 말해 1번 노드 기준이므로 0 ~ 3열을 기본 전제로 깔고 가는 것이다.
위 segment tree에서 root node는 0 ~ 3행에 대한 부분합이다. 더 자세히 말하면 0 ~ 3열 + 0 ~ 3행에 대한 부분합이다. 즉, (0,0) ~ (3,3)에 대한 부분합이다. 그림으로 표현하면 노란색 영역과 주황색 영역이 겹치는 부분이다. (0,0) ~ (3,3)의 부분합이 64인데, 이 값은 열에 대한 segment tree에서 1번 노드의 행에 대한 segment tree의 1번 노드 값인 것이다.
사실, 열에 대한 segment tree의 node 값에 행에 대한 segment tree 자체를 넣는다는 것이 잘 이해가 가질 않았다. 코드로 이해해보자. 먼저 1차원 segment tree에서 쿼리를 구하는 함수는 아래와 같다.
def query(node, start, end, left, right):
if left <= start and end <= right:
return tree[node]
if end < left or right < start:
return 0
return subsum(node*2, start, (start+end)//2, left, right) + subsum(node*2 + 1, (start+end)//2 + 1, end, left, right)재귀적으로 부분합을 구하되, return하는 값은 트리의 노드 값이다.
하지만 2차원 segment tree에서는 열에 대한 쿼리 함수가 행에 대한 쿼리 함수의 리턴값을 리턴한다.
def yquery(ynode, start, end, left, right, x1, x2):
if left <= start and end <= right:
return xquery(ynode, 0, n-1, 1, x1, x2)
if end < left or right < start:
return 0
return yquery(ynode*2, start, (start+end)//2, left, right, x1, x2) + \
yquery(ynode*2 + 1, (start+end)//2 + 1, end, left, right, x1, x2)그리고 행에 대한 쿼리 함수는 최종적으로 관심있는 열(ynode)에서 관심있는 행(xnode)에 대한 부분합을 반환한다.(tree[ynode][xnode])
def xquery(ynode, start, end, xnode, left, right):
if left <= start and end <= right:
return tree[ynode][xnode]
if end < left or right < start:
return 0
return xquery(ynode, start, (start+end)//2, xnode*2, left, right) + \
xquery(ynode, (start + end)//2 + 1, end, xnode*2 + 1, left, right)즉, xquery 함수를 호출할 때, ynode 값을 인자로 넘겨주고 이 값이 관심있는 열의 범위를 뜻한다. 그리고 재귀적으로 관심있는 행의 범위를 포함하는 xnode 값을 찾았을 때, 그 값을 반환함으로써 부분합을 구하는 것이다.
초기 트리를 init하는 함수도 비슷하게 yinit을 처음에 호출하고, 시작점과 끝점이 동일하면 ( = if 절에 걸리면) xinit 함수를 호출하는 방식으로 작동한다.
먼저 yinit 함수이다.
def yinit(ynode, start, end):
if start == end:
return xinit(ynode, 0, n-1, 1, start)
yinit(ynode*2, start, (start+end)//2)
yinit(ynode*2 + 1, (start+end)//2 + 1, end)
for k in range(len(tree[0])):
tree[ynode][k] = tree[ynode*2][k] + tree[ynode*2 + 1][k]주목할만한 점은 왼쪽 자식노드, 오른쪽 자식 노드에 대해 yinit 함수를 재귀적으로 모두 호출하고 난 후에 for 문을 통해 자식 노드의 상위 노드, 부모 노드의 값을 구한다는 것이다. 이를 통해 모든 xnode에 대해 (for문은 xnode에 대해 돌아감) 자식 노드의 양쪽 값을 더함으로써 그들의 부모 노드 값을 구한다.
다음으로 xinit 함수이다.
def xinit(ynode, start, end, xnode, yidx):
if start == end:
tree[ynode][xnode] = l[start][yidx]
return tree[ynode][xnode]
tree[ynode][xnode] = xinit(ynode, start, (start+end)//2, xnode*2, yidx) + \
xinit(ynode, (start + end) // 2 + 1, end, xnode * 2 + 1, yidx)
return tree[ynode][xnode]이는 yinit 함수에서 ynode 값을 받아오는 것 외에 일반적인 segment tree의 init 함수 구조랑 비슷하다.
마지막으로 트리를 update 하는 함수도 처음에 yupdate을 호출하고, 재귀적으로 xupdate을 호출하는 방식이다.
def xupdate(ynode, xnode, start, end, xidx, diff):
if not (start <= xidx <= end):
return
tree[ynode][xnode] += diff
if start != end:
xupdate(ynode, xnode*2, start, (start+end)//2, xidx, diff)
xupdate(ynode, xnode*2 + 1, (start+end)//2 + 1, end, xidx, diff)
def yupdate(ynode, start, end, yidx, xidx, diff):
if not (start <= yidx <= end):
return
xupdate(ynode, 1, 0, n-1, xidx, diff)
if start != end:
yupdate(ynode*2, start, (start+end)//2, yidx, xidx, diff)
yupdate(ynode*2 + 1, (start+end)//2+1, end, yidx, xidx, diff)시간 복잡도, 공간복잡도
하나의 쿼리를 처리하는 시간에 대해서 생각해보자. segment tree 안에 segment tree가 있다. 첫 번째 segment tree을 탐색하는데는 $O(logn)$의 시간이 걸리고 그럴 때마다 두번째 segment tree을 탐색해야하니까 총 $O((logn)^2)$의 시간이 걸린다. 근데 이 쿼리를 총 $m$번 처리해야하므로 최종 시간 복잡도는 $O(m(logn)^2)$이다.
이 문제에서는 약간의 공간 복잡도을 희생함으로써 시간 복잡도를 확보했다고 볼 수도 있다. 소스 코드를 보면 tree라는 2차원 배열이 필요하고 $h = ceil(log_2(n))$이라고 둘 때, $2^{(h+1)} \times 2^{(h+1)}$의 공간이 필요하다. 이 문제에서는 $1 \leq n \leq 1024$이기 때문에 $2048 \times 2048$의 공간, 다시 말해 $2048 \times 2048 \times 4 = 16777216KB = 16MB$의 공간이 필요하다. 만약 n의 제한이 커진다면 효율적인 메모리를 사용하는 자료구조도 고려할 필요가 있을 것이다.
[Source Code]
from math import ceil, log2
import sys
input = sys.stdin.readline
def xinit(ynode, start, end, xnode, yidx):
if start == end:
tree[ynode][xnode] = l[start][yidx]
return tree[ynode][xnode]
tree[ynode][xnode] = xinit(ynode, start, (start+end)//2, xnode*2, yidx) + \
xinit(ynode, (start + end) // 2 + 1, end, xnode * 2 + 1, yidx)
return tree[ynode][xnode]
def yinit(ynode, start, end):
if start == end:
return xinit(ynode, 0, n-1, 1, start)
yinit(ynode*2, start, (start+end)//2)
yinit(ynode*2 + 1, (start+end)//2 + 1, end)
for k in range(len(tree[0])):
tree[ynode][k] = tree[ynode*2][k] + tree[ynode*2 + 1][k]
def xquery(ynode, xnode, start, end, left, right):
if left <= start and end <= right:
return tree[ynode][xnode]
if end < left or right < start:
return 0
return xquery(ynode, xnode*2, start, (start+end)//2, left, right) + \
xquery(ynode, xnode*2 + 1, (start + end) // 2 + 1, end, left, right)
def yquery(ynode, start, end, left, right, x1, x2):
if left <= start and end <= right:
return xquery(ynode, 1, 0, n-1, x1, x2)
if end < left or right < start:
return 0
return yquery(ynode*2, start, (start+end)//2, left, right ,x1, x2) + \
yquery(ynode*2 + 1, (start + end) // 2 + 1, end, left, right, x1, x2)
def xupdate(ynode, xnode, start, end, xidx, diff):
if not (start <= xidx <= end):
return
tree[ynode][xnode] += diff
if start != end:
xupdate(ynode, xnode*2, start, (start+end)//2, xidx, diff)
xupdate(ynode, xnode*2 + 1, (start+end)//2 + 1, end, xidx, diff)
def yupdate(ynode, start, end, yidx, xidx, diff):
if not (start <= yidx <= end):
return
xupdate(ynode, 1, 0, n-1, xidx, diff)
if start != end:
yupdate(ynode*2, start, (start+end)//2, yidx, xidx, diff)
yupdate(ynode*2 + 1, (start+end)//2+1, end, yidx, xidx, diff)
n,m = map(int,input().split())
h = int(ceil(log2(n)))
tree = [[0]*(2**(h+1)) for _ in range(2**(h+1))]
l = []
for _ in range(n):
l.append(list(map(int,input().split())))
yinit(1,0,n-1)
for _ in range(m):
cur = list(map(int,input().split()))
if cur[0] == 0:
_,x,y,c = cur
diff = c-l[x-1][y-1]
l[x-1][y-1] = c
yupdate(1,0,n-1,y-1,x-1,diff)
else:
_,x1,y1,x2,y2 = cur
print(yquery(1, 0, n-1, y1-1, y2-1, x1-1, x2-1))'Programming > BOJ' 카테고리의 다른 글
| [segment tree] 1777번 순열복원 (0) | 2022.04.24 |
|---|---|
| [segment tree] 1849번 순열 (0) | 2022.04.09 |
| [segment tree] 2243번 사탕상자 (0) | 2022.04.08 |
| [segment tree] 11505번 구간 곱 구하기 (0) | 2022.03.20 |
| [구현] 2174번 로봇 시뮬레이션 (0) | 2022.03.17 |




댓글