- 논문 링크(29회 인용)
개인적으로 추천시스템의 여러 모델을 리뷰하고 pytorch 또는 numpy로 구현하는 프로젝트를 진행하고 있다. (PR은 언제나 환영!)
https://github.com/bohyunshin/recommender
GitHub - bohyunshin/recommender: Implementation of various recommender algorithm
Implementation of various recommender algorithm. Contribute to bohyunshin/recommender development by creating an account on GitHub.
github.com
아직 초기 단계로, 추천 시스템의 가장 기본인 행렬 분해 (matrix factorization)부터 구현해보고 있던 와중에.. svd을 통해서 유저/아이템 벡터를 학습시키는 것은 아래의 loss function을 최소화하도록 학습을 진행함으로써 비교적(?) 쉽게 구현할 수 있었다.
\[ L = \sum_u \sum_i ( r_{ui} - \mathbf{p}^T_u \mathbf{q}_i )^2 \]
위의 손실함수에서 $r_{ui}$는 보통 유저가 아이템에 대해 직접적으로 남긴 평점을 의미한다. 즉, explicit feedback data이다. 생각해보면 유저 x 아이템 행렬에서 평점을 남기는 경우는 그리 많지 않으니.. 위 loss function에 대해 pytorch에서 SGD로 학습을 진행해도 큰 무리는 없어 보였다.
문제는 explicit feedback 데이터가 아닌, implicit feedback 데이터일 때이다. implicit feedback에서 collaborative filtering을 어떻게 하는지에 대한 논문은 아래 포스팅에서 자세하게 살펴보았다.
https://steady-programming.tistory.com/45
[Recommender System / Paper review] #07 Collaborative Filtering for Implicit Feedback Datasets
논문 링크(3690회 인용)Summary사용자가 직접적으로 아이템에 대해 매기는 explicit feedback이 아닌, implicit feedback 데이터를 이용하여 unknown preference을 예측하는 방법을 제안한다.implicit feedback은 explicit
steady-programming.tistory.com
유저가 상호작용을한 아이템만 학습에 사용하는 explicit feedback 데이터와는 달리, 상호작용을 하지 않은 아이템도 사용하는 implicit feedback 데이터에서는 기본적으로 데이터의 크기가 매우 크다. 유저의 수 x 아이템의 수만큼 데이터가 나오기 때문이다. 이렇게 큰 데이터에 대해 SGD로 학습을 진행하면 비효율적이기 때문에 위 논문에서는 alternative least squares을 제안한 것이다.
여기까지는 원래 이해하고 있던 내용이었는데.. 정말로 implicit feedback 데이터에서는 유저가 상호작용을 하지 않은 아이템의 데이터도 모두 사용할까? 라는 의문이 들었다. 예를 들어서, 아이템이 1만개 있고, 한 유저가 1만개 중에 상호작용(아이템을 클릭했거나 구매한 경우 등)을 한 아이템이 20개정도라고 하자. 그러면 이 유저의 positive sample은 20개이고, negative sample은 (1만 - 20)개인 것이다. 뭔가 얼핏봐도 학습이 편향되게 진행될 것 같은 느낌이 들어서 관련 논문을 살펴보니, 이전 연구 동향이 크게 두 부류였다. 정통(?) implicit feedback 데이터를 사용하는 방법으로 샘플링을 하지 않고 모든 negative 샘플을 사용하는 것이고 (non sampling) 샘플링 전략에 따라서 샘플을 하는 negative sampling이 있었다.
이번에 리뷰할 서베이 논문은 implicit feedback 데이터를 모델링할 때, negative sampling을 어떻게 처리하는지에 대한 연구 동향을 다룬다. non-sampling 전략과 negative sampling 전략을 소개하고 각 전략의 장단점 및 진행된 연구를 리뷰한다. 이 논문은 1) 다양한 negative sampling 전략을 소개하고 2) non sampling 전략을 택할 때, 단점을 극복하기 위한 여러 논문을 소개해서 특히 더 유익하다고 느껴졌다. 그러면, 논문의 내용을 본격적으로 살펴보자.
Summary
- 현실세계에서 평점데이터와 같이 유저의 선호를 직접적으로 알 수 있는 explicit feedback 데이터보다는, 유저의 선호를 간접적으로 알 수 있는 implicit feedback 데이터가 더 흔하게 존재한다.
- implicit feedback 데이터는 positive sample에 비해 negative sample이 훨씬 더 많이 존재하는데, 그 negative sample이 실제로 유저의 dislike을 직접적으로 나타내지 않는다는 문제점이 있다.
- 그에 따라서 implicit feedback 데이터를 이용한 연구는 negative sample에서 의미있는 샘플을 추출해서 학습하는 negative sampling 기법과 negative sample을 전부 사용하는 non-sampling 기법으로 나뉜다.
- negavie sampling 기법은 더 효율적인 학습이 가능하지만 샘플링된 negative sample의 퀄리티에 영향을 받고 수렴이 느리다.
- non sampling 기법은 일반적으로 더 나은 성능을 보이지만 비효율적인 학습이 문제다.
- 본 논문에서는 실험을 통해 두 기법의 성능을 비교해보는데, uniform weighted non-sampling 학습법이 다수의 negavie sampling 기법의 성능보다 더 좋음을 보인다.
- 이를 통해 다수의 언구에서 baseline에 non sampling 기법이 포함되지 않는데, 이를 지적하며 앞으로의 implicit feedback 데이터 연구 방향성을 제시한다.
Understanding negative sampling and non-sampling

논문에서 사용할 노테이션을 짚고 넘어가자.
Negative sampling
negative sampling을 이용한 implicit recommendation은 크게 세가지 component을 가진다. scoring function인 $\hat{y}$, objective function인 $\mathcal{L}$, 그리고 negative sampling 전략인 $p_{ns}$이 그것들이다. scoring function은 보통 유저와 아이템의 latent factor의 함수로 구성된다. 수식으로 표현하면, $\hat{y}(\mathbf{p}_u, \mathbf{q}_i, \mathcal{\theta})$ 이다. 보통 matrix factorization이나 neural networks을 사용한다. negative sampling 기반의 추천 모델에서는 objective function으로 bpr을 많이 사용한다.

여기서 negative sample을 $p_{ns}(j | u)$ 분포로부터 샘플링한다. i는 positive sample이고, j는 negative sample이므로 $\sigma( \hat{y}(u,i) - \hat{y}(u,j) )$는 유저 u가 아이템 i에 비해 j을 더 선호할 likelihood을 모델링한다. $\mathcal{L}$을 minimize하기 위해 $\sigma( \hat{y}(u,i) - \hat{y}(u,j) )$을 maximize 해야하고, 이는 곧 $ \hat{y}(u,i) $와 $\hat{y}(u,j)$의 차이를 크게 만드는 것과 동일하다.
BPR 목적 함수의 gradient는 아래와 같다.
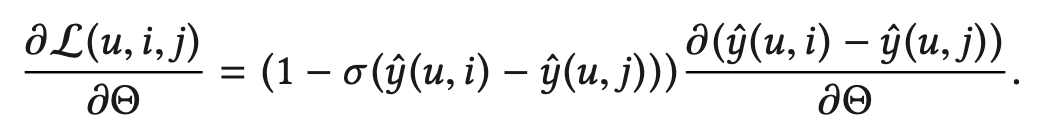
만약에 샘플링된 negative sample이 right example이라면, (정말로 유저 u에게 negative sample) $\sigma( \hat{y}(u,i) - \hat{y}(u,j) )$은 1에 가까울 것이고 해당 (i,j) pair에 대한 gradient는 0에 가까워진다. 즉, 학습에 별 다른 도움을 주지 못하는 것이다. 이런 이슈는 sampling 분포가 uniform일 때 더 잘 나타난다.
추천 시스템에서 아이템 인기도는 보통 non-uniform하며 positive 관측치는 tailed 분포를 가진다. 따라서 uniform하게 뽑힌 아이템 j의 score, $\hat{y}(u,j)$는 $\hat{y}(u,i)$에 비해 작을 가능성이 높다. 따라서 uniform sampling 전략은 optimal 성능을 달성하기 힘들고 수렴이 느린 것이다.
이것을 피하기 위해 샘플링 시에 아이템의 점수를 활용하는 이전 연구들이 제안되었다. (AOBPR, BPR-DNS) 이 연구들은 좀 더 어려운 샘플을 뽑도록 디자인된다. 즉, negative sample 중에 높은 점수를 가지는 샘플을 뽑아서 $\sigma( \hat{y}(u,i) - \hat{y}(u,j) )$의 값을 줄이고 gradient의 영향도를 살리는 것이다. 하지만 이것의 문제점은, 높은 점수를 가지는 negative sample 자체가 사실, false negative일 가능성이 있기 때문에, 모델의 성능에 영향을 줄 수 있다.
위 논의를 통해 netavie 샘플을 뽑는 것의 어려움, 높은 점수를 가지는 negative sample을 뽑았을 때 수렴의 문제점과 false negative을 뽑을 위험에 대해 알아보았다.
Non-sampling
non-sampling 학습 전략을 이용한 추천 시스템은 관측되지 않은 샘플을 모두 negative label로 간주한다.

많이 사용되는 목적 함수는 weighted regression function이다.

이 목적 함수를 통해 학습된 모델은 모든 negative sample을 사용하기 때문에 모든 값을 0으로 예측하고 그에 따라서 제대로된 랭킹을 하지 못할 가능성이 있다. 또한 결측 데이터가 상호작용한 데이터보다 훨씬 많기 때문에 class imbalance issue을 해결하기 위해 weight을 조절할 필요가 있다. non-sampling 전략에서 negative sample에 대해 어떤 weight을 줄 것인지에 대한 연구도 진행되었는데 이는 곧 negative sampling 전략에서 어떻게 샘플링할 것인지에 대한 생각와 유사하다. 어찌됐든 non-sampling 전략은 모든 negative sample을 사용한다는 단점이 있다는 것을 기억하자.
Methods for empirical study
크게 negative sampling과 non-sampling으로 나뉘고 negative sampling에서는 BPR-Uniform sampling AOBPR, BPR-DNS, IRGAN, SRNS을, non-sampling에서는 WMF, EALS을 살펴본다.
BPR-Uniform sampling
BPR pair-wise loss function에서 가장 많이 사용되는, 클래식한 샘플링 기법이다. 가장 간단한 uniform 샘플링 구조를 사용하기 때문에 random sampling이라고 불리기도 한다. positive pair인 $(u,i)$에 대한 negative item $j$을 뽑기 위해서 아래의 $Q(j | u,i)$ 확률 분포를 사용한다.
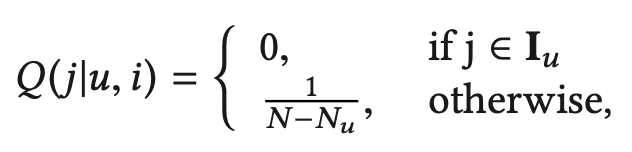
$N_u$는 유저 u가 상호작용한 아이템의 수이다. 이 샘플링 기법은 위에서 살펴보았듯이, 아이템 인기도가 보통 tail 분포이고, 이런 경우에 gradient의 영향도가 미미해져서 수렴을 늦게한다는 단점이 있다.
AOBPR
Adaptive Oversampling BPR은 어려운 예시를 샘플링함으로써 uniform sampling 전략을 개선하고자 한다. 어려운 예시, 즉 관측되지 않았지만 높은 점수를 가지는 샘플을 의도적으로 뽑는다. 해당 샘플은 모델이 구분하기 어려울 것이므로 이를 학습하면 추후에 더 좋은 추천을 할 수 있을 것이라 생각하는 것이다. AOBPR은 점수를 직접적으로 사용하지는 않고 랭킹을 사용한다. 점수가 높으면 랭킹이 높고, 그러면 더 informative할 것이다. 따라서 이러한 informative한 샘플을 뽑도록 디자인한다.

여기서 $\hat{r}(u,j)$는 score function을 사용한 아이템 j의 랭킹이다. AOBPR는 위 샘플링 전략을 사용하기 위해서 모든 아이템의 점수를 계산해야하고 높은 점수를 가지는 아이템은 오히려 false negative일 가능성이 있다는 것이 단점이다. 따라서 uniform sampling보다 false negative 샘플에 더 취약하다.
BPR-DNS
BPR-DNS (Dynamic negative sampling)은 AOBPR과 유사하지만 처음 negative samples을 랜덤하게 뽑고 그 중에 가장 높은 점수를 가지는 아이템만 사용한다.

BPR-DNS는 모든 샘플의 점수를 계산하지 않는다는 장점이 있지만, 여전히 AOBPR과 비슷하게 false negative에 취약하다는 단점이 있다.
IRGAN
GAN 스타일의 negative sampling 방법으로, implicit 추천 문제와 같은 information retrieval 문제에 mini-max 게임 이론을 적용한다. Generator는 더 어려운 negative sample을 생성하고 Discriminator는 discrimination objective function인 $\mathcal{J}(D,G)$을 최소화한다.

목적 함수는 위와 같다. 이상적으로 학습이 잘 될면, negative sample을 G로부터 생성한다. 이러한 GAN 스타일의 방법은 꽤나 좋은 효과를 보이는데, 다만 Generator로부터 negative sample을 생성하는데 시간이 오래걸린다는 단점이 있다.
SRNS
SRNS (Simplified and robust negative sampling)는 학습 epoch에서 높은 점수를 가지는 false-negative sample을 찾는다. 이 방법은 좀 어려우니.. 나중에 따로 리뷰를 하는 것으로!
WMF
Weighted MF는 대표적인 non-sampling 기법으로 관측되지 않은 negative sample에 가중치를 주는 방법이다. WMF는 그 중에서도 동일한 가중치를 준다.
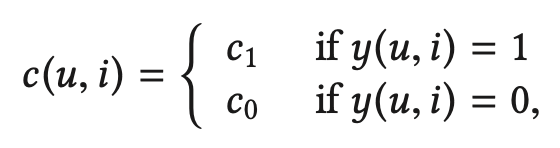
본 서베이 논문에서 가중치가 positive sample일 때도 동일하게 $c_1$이라고 나와있는데, WMF을 제안한 논문에서는 $c_{ui} = 1 + \alpha r_{ui}$ 또는 $c_{ui} = 1 + \alpha \log (1 + r_{ui} / \epsilon )$으로 제안한다. 본 서베이 논문에서는 $c_0$을 [0.001, 0.005, 0.01, 0.05, 0.1, 0.3, 0.7]에서 파라미터 튜닝했다. 보통, 데이터가 sparse할 수록 $c_0$ 값이 작은게 좋다고 한다.
EALS
WMF는 관측되지 않은 아이템에 대해 $c_0$라는 동일한 가중치를 주는데, 이는 비현실적이다. 아이템마다 인기도가 다를 것이기 때문이다. EALS는 이를 개선하기 위헤 관측되지 않은 아이템에 대해 서로 다른 가중치를 아래와 같이 준다.
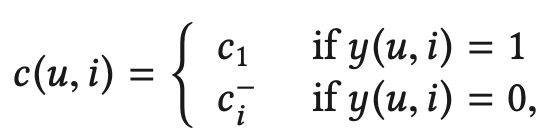
여기서 $c^{-}_{i}$는 아래와 같이 정의된다.

자세한 내용은 아래 포스팅을 참고하자.
https://steady-programming.tistory.com/57
[Recommender System / Paper review] #19 Fast Matrix Factorization for Online Recommendation with Implicit Feedback
논문 링크(967회 인용) Summary 기존의 방법과는 다르게, 본 논문에서 제안하고자 하는 mf는 implicit feedback을 이용하되 관측되지 않은 feedback은 서로 다른 weight을 준다. 이는 item popularity을 반영한 weigh
steady-programming.tistory.com
Experiments
Data
- movielens-1m
- yelp2018
- alibaba
Evaluation metric
- Recall
- Normalized discounted cumulative gain (NDCG)
Results
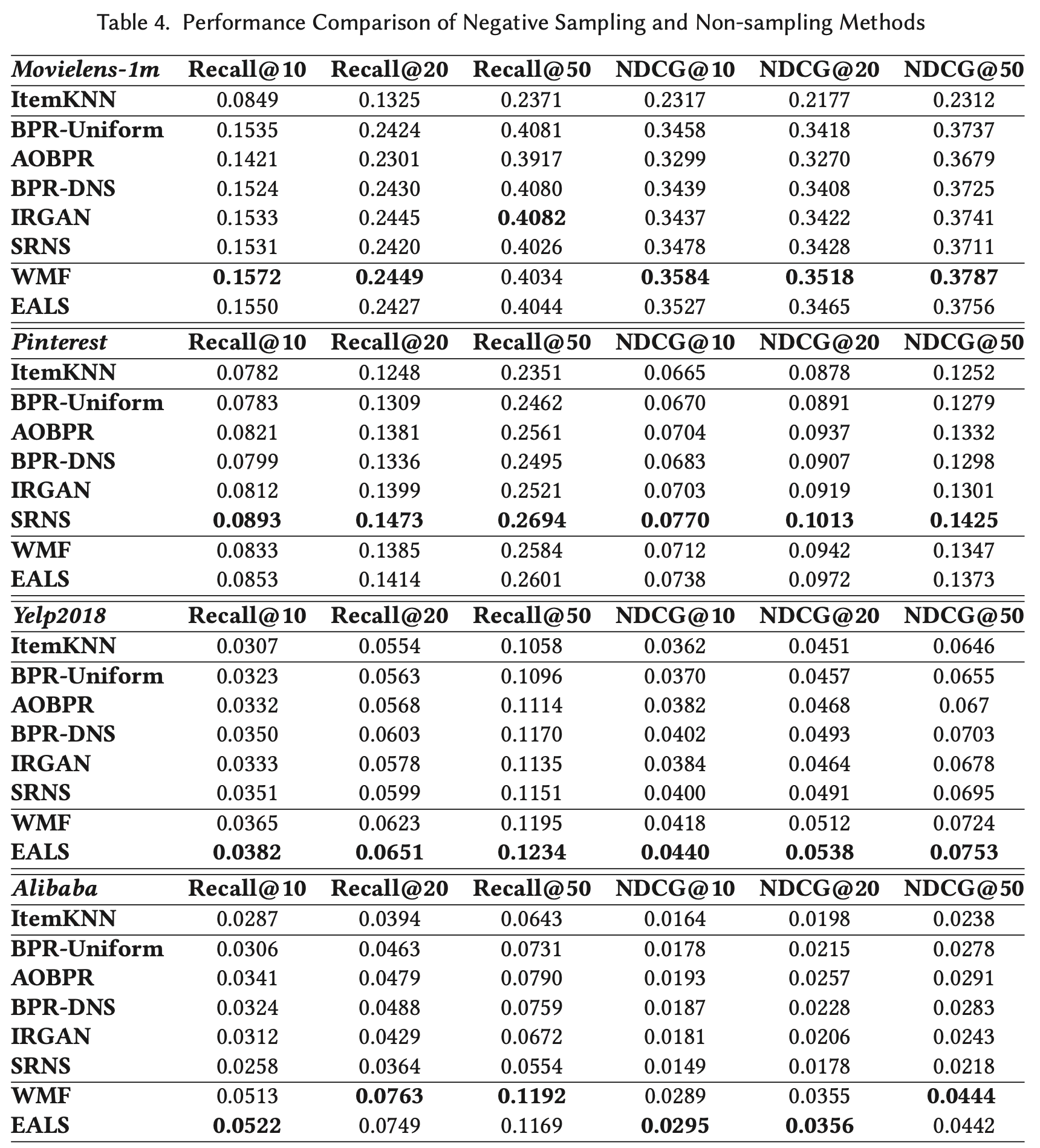
- BPR-Uniform에 비해서 non-sampling 방법이 전체적으로 더 좋은 성능을 보인다.
- 이는 uniform sampling을 하면 positive sample, negative sample을 구분하기가 쉬워져 gradient가 0에 가까워지기 때문에 파라미터 학습이 잘 안된다는 이전 연구 내용과 유사하다.
- Negative sampler가 좋을수록 topk 추천에서 더 좋은 성능을 보인다.
- BPR-Uniform에 비해서 AOBPR, BPR-DNS, IRGAN, SRNS가 전체적으로 더 좋은 성능을 보인다.
- 특히, SRNS가 가장 나은 성능을 보이는 경향이 있다.
- negative sample의 informativeness와 reliability을 모두 보기 때문이다.
- AOBPR, BPR-DNS는 false negative 문제가 있기 때문에 상대적으로 낮은 성능을 보인다.
- WMF가 SOTA negative sampling 방법보다 더 나은 성능을 보인다.
- 특히, $c_0$을 세밀하게 튜닝하는 것이 매우 중요한데, 이전 연구에서는 이런 노력이 부족했다.
- 따라서 이전 연구에서는 negative sampling이 WMF와 비슷한 결과를 보이는 경우가 많았다.
- 본 논문은 다양한 값으로 튜닝했기 때문에 이전 연구와는 다른 결과를 얻은 것이다.
- EALS가 WMF에 비해 더 나은 성능을 보인다.
- 아무래도 아이템 인기도에 따라서 negative sample에 대해 다른 가중치를 주기 때문일 것이다.
- 데이터의 특성을 생각해볼 때, 더 sparse한 데이터일수록 non-sampling 방법이 negative sampling 방법에 비해 더 나은 성능을 보인다.
- movielens부터 alibaba까지 sparsity가 점점 낮아지는데, movielens에서 negative sampling과 non-sampling의 차이에 비해 alibaba에서의 차이가 훨씬 더 크다.
- 이는 곧, sparsity가 높은 데이터에서는 제대로된 negative sampling을 하기 힘들고, 이는 성능 하락으로 이어짐을 의미한다.
Impact of sampling number
여기까지 non-sampling 방법과 negative sampling 방법을 살펴보았는데, 그렇다면 negative sampling 방법에서는 몇개의 negative sample을 뽑을까? 보통 이전 연구에서 positive user-item pair별로 한개의 negative sample을 뽑는다고 한다. 그러면 여러개의 negative sampling number을 뽑는다면 어떻게 될까? 아래의 그림을 살펴보자.

확실히 하나의 positive pair별로 더 많은 수의 negative sample을 뽑으면 성능도 올라가고 빨리 수렴하는 것을 확인할 수 있다. 개인적인 생각으로는, 4이상으로 가면 크게 차이가 나지 않기 때문에 학습 시간을 봐가면서 적절히 튜닝해야할 것 같았다.
Conclusion
이 서베이 논문을 통해서 implicit 추천 시스템에서 어떤 challenges가 있는지, 그걸 해결하기 위해 어떤 연구 흐름이 있었는지, 그리고 데이터 sparsity에 따라서 어떤 sampling을 사용하는게 좋은지 알 수 있어서 매우 유익한 시간이었다. 논문 정리로 끝나는게 아니라 이제 직접 실험을 해봄으로써 대충 이정도 데이터에서는 어떤 negative sampling을 사용하는게 좋겠구나 라는 감을 잡으면 가장 좋지 않을까 싶다.




댓글