[Recommender System / Paper review] #32 Denoising Self-Attentive Sequential Recommendation
- 논문 링크(14회 인용, Awarded as 2022 Recsys Best paper)
Summary
- attention을 사용한 transformer-based 추천 모델의 단점은 noisy한 데이터가 많은 가운데, 모든 아이템에 대한 attention을 계산한다는 것이다.
- 이를 보완하기 위한 방법으로 sparse transformer 등의 방법이 제안됐는데, 본 논문에서는 zero masking learning을 제안하여 데이터로부터 어떤 아이템에 대한 attention을 계산하지 않을 것인지 학습하는 알고리즘을 제안한다.
- 이런 indicator variable을 도입하면 미분가능하지 않고 추정치의 분산이 매우 커지는 단점이 있는데, 이를 efficient gradient computation을 통해 극복한다.
- 또한 dot-product self-attention이 Lipschitz continuous하지 않기 때문에 input sequences에 민감하다는 최근 연구 결과를 바탕으로, 좀 더 robust한 모델을 만들기 위해 jacobian regularization을 사용한다.
Motivation
- attention을 사용한 transformer-based 모델은 BERT 등을 통해 sequential problem인 machine translation에서 우수한 성능을 거두었고, 추천 시스템에서 비슷한 문제인 sequential recommendation 문제를 풀기 위해 사용되기 시작했다.
- 기본적으로 transformer-based 모델은 rnn, cnn에 비해서 단어들간의 long-term 관계를 더 잘 모델링하고 이 특징이 sequential recommendation에서도 그대로 사용됐다.
- 하지만 transformer-based 모델도 단점은 있었으니. 그것은 바로 모든 단어들, 어쩌면 [sep], "."와 같은 필요 없는 단어들까지도 포함하여 attention을 계산한다는 것이고 때른 이 단어들간의 관계가 더 중요하다고 나오는 문제가 제기됐다.
- 추천시스템도 마찬가지이다. 추천시스템의 데이터는 기본적으로 implicit하며, 이 데이터는 noisy하다. noisy한 아이템에 대해서 모두 attention을 계산하면 비효율적일 뿐만 아니라 결과가 왜곡되어서 나올 수 있다.
- 본 논문은 이런 문제를 해결하기 위해 선택적인 attention이 핵심인 Rec-denoiser을 제안한다. 이전에도 sparse transformer 등의 형태로 비슷한 생각이 많이 제시되었으나 본 논문에서는 masking을 통해 불필요한 아이템에 대해서는 아예 attention을 계산하지 않는다는 점, 그리고 여러 computation 트릭을 통해 robust model을 만든다는 점에서 이전의 방법들과는 차별점을 보인다.
Approach
Problem Setup
- $U,I$: set of users and items
- $S = \{ S^1, S^2, \cdots, S^{|U|} \}$: set of users' actions
- $S^u = ( S^u_1, S^u_2, \cdots, S^u_{|S^u|} )$: $u \in U$에 대한 시간에 따른 아이템 순서
- $S^u_t \in I$: 유저 u가 t 시점에서 상호작용한 아이템
- $|S^u|$: sequence의 길이
- 유저 u의 아이템에 대한 sequence인 $S^u$가 주어졌을 때, 유저 u가 다음에 어떤 아이템을 선호할지, $S^u_{|S^u+1|}$을 timestamp $|S^u + 1|$에 예측하는 문제이다.
Self-attentive Recommenders
Rec-denoiser는 기본적으로 transformer과 추천시스템이 합쳐진 모델이다. 즉, 이전의 SASRec, BERT4Rec과 비슷한 모델 구조를 가지기 때문에 간단하게 SASRec의 구조와 이 모델의 한계에 대해 짚고 넘어가자.
Embedding Layer
- 입력 아이템을 $\mathbf{T} \in \mathbb{R}^{|I| \times d}$의 embedding matrix을 통해 임베딩 벡터로 변환한다.
- $S^u = ( S^u_1, S^u_2, \cdots, S^u_{|S^u-1|} )$ 을 fixed length sequence인 $(s_1, s_2, \cdots, s_n)$으로 변환하는 것이다. 이때 $n$은 hyperparameter인데 가장 최근의 몇개의 아이템까지 둘 것인지를 결정한다.
- $(s_1, s_2, \cdots, s_n) = \mathbf{E} \in \mathbb{R}^{n \times d}$는 어떤 아이템이 먼저 등장했는지, 순서에 대한 개념이 전혀 없다.
- nlp에서 단어의 순서를 인지시키기 위해 positional embedding을 추가하듯이, SASRec도 동일한 과정을 거친다. $\hat{\mathbf{E}} = \mathbf{E} + \mathbf{P}$
- 이제 $\hat{\mathbf{E}}$가 transformer의 input으로 들어간다.
Transformer Block - Self attention layer
transformer의 꽃이라고 할 수 있겠다. query, key, value vector을 통해 scaled-dot-product attention을 계산한다.

이때 $\mathbf{Q}, \mathbf{K}, \mathbf{V}$는 projection 행렬을 통해 나온 query, key, value matrix이다.
Transformer Block - Point-wise Feed-forward Layer
transformer에서 했던 것과 동일하게 self-attention vector가 나왔으면 이를 feed-foward nn을 태운다.

Learning objective
$L$개의 transformer blocks을 쌓으면, 이제 최종으로 우리가 원하는 것을 얻어야 한다. 우리는 기존 n개의 아이템이 주어졌을 때 n+1번째 아이템에는 어떤 것이 올지에 대한 문제를 풀고 있었다. $L$번째 transformer block 후에는 이전 아이템에 대한 attention이 녹아있는 $\mathbf{F}^{L}_t$ 벡터가 나올 것이고 이 벡터를 다른 아이템의 벡터와 내적함으로써 relevance을 구한다.

여기서 모델의 input sequence인 $(s_1, s_2, \cdots, c_n)$은 도일한 sequence $\mathbb{o} = (o_1, o_2, \cdots, o_n)$의 shifted version임을 기억해보자. 그러면 $o_t, t$가 동일할 확률을 $r_{o_t, t}$로 나타낼 수 있고 이에 대한 binary cross-entropy로 loss을 아래와 같이 세울 수 있다.
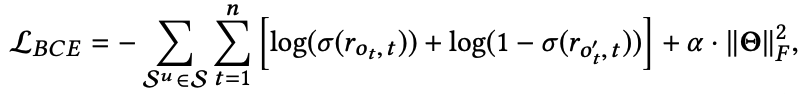
The noisy attention problems
- SASRec은 기본적으로 full attention 알고리즘이기 때문에 dense하다. 따라서 관련되지 않은 아이템에 대해 credits을 배정할 수 있다.
- 게다가 추천 시스템에서 유저의 행동 데이터가 기본적으로 implicit하다는 점을 생각해보면, 이 단점이 더 드러날 수 있다.
- 본 논문은 필요 없는 관계에 대해서는 attention을 계산하지 않되, 이를 데이터를 통해서 학습하는 방법을 제시한다.
Rec-Denoiser: Differentiable masks
- self attention layer는 transformers의 핵심 부분이지만 때로는 불필요한 관계까지 학습할 때가 있다.
- 미분 가능한 (differentiable) 마스크 (masks)로 불필요한 부분을 조절해보자.
Learnable sparse attentions
$l$번째 self-attention layer에서 binary matrix인 $\mathbf{Z}^{(l)} \in \{ 0,1 \}^{n \times n}$을 생각해보자. 여기서 $\mathbf{Z}^{(l)}_{u,v}$는 query $u$와 key $v$간의 connection이 있는지, 그 여부를 나타내는 binary value이다. 이 binary matrix을 통해 계산된 self-attention에 sparsity을 부여하는 것이다.
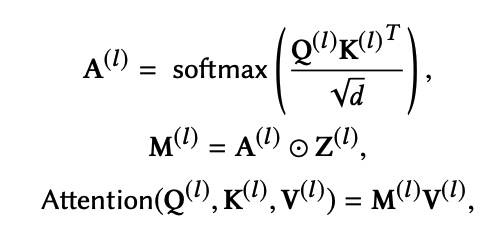
잘 보면, $\mathbf{A}^{(l)}$은 기존의 attention matrix이고 $\mathbf{Z}^{(l)}$을 elementwise하게 곱해서 masking을 하는 것을 알 수 있다.
여기서 $\mathbf{M}^{(l)}$의 sparsity을 encourage하는 방법은 마치 lasso에서 $L_0$ norm을 부여하는 것처럼, 여기서도 $\mathbf{Z}^{(l)}$의 non-zero entries의 수를 명시적으로 penalize하는 것이다.

$L_0$ norm은 명시적으로 sparsity을 부여하는 장점을 가지지만 differentiable하지 않다는 단점을 가지고 있다. 게다가 이 문제에서는 $\mathbf{Z}^{(l)} \in \mathbb{R}^{n \times n}$이기 때문에, binary matrix의 상태 가짓수가 $2^{n^2}$라는 단점이 있다. 이제 이러한 문제를 어떻게 풀어나가는지 살펴보자.
Efficient gradient computation
binary cross entropy와 $L_0$ norm을 섞어서 만든 목적식은 아래와 같다.

- $\beta$는 binary mask의 sparsity을 결정한다.
- $\mathbf{Z}^{(l)_{u,v}} \sim Ber(\prod^{(l)}_{u,v})$, 즉 베르누이 분포에서 뽑힌다고 가정한다.
- 다시 말해, $\prod^{(l)}_{u,v}$가 작다면 1이 나올 가능성이 적다는 것이니까 key, query가 불필요한 관계일 가능성이 높다고 해석할 수 있다.
이를 반영해서 objective function을 다시 적어보면 아래와 같다.

여전히 $\mathcal{L}_{BCE}$는 binary variables인 $\mathbf{Z}^{(l)}$을 초함하고 있다. 이를 해결하기 위해 gradient estimators인 REINFORCE, Straight Through Estimator 등을 사용할 수 있으나 biased gradients이거나 분산이 크다. 본 논문에서는 최근에 제안된 augment-REINFORCE-merge (ARM)을 통해 unbiased하고 분산이 작은 gradient estimator을 구하고자 한다. gradient을 구체적으로 어떻게 구하는지는 생략하겠다! 논문을 참조하길 바란다.
Jacobian regularization
최근의 연구 결과에 의하면 dot-product self-attention은 Lipschitz continuous하지 않고 input sequences의 quality에 취약하다. 추천시스템에서 input data는 implicit한 경우가 많기 때문에 이런 연구 결과에 주목할 필요가 있을텐데 본 논문에서는 Jacobian regularization을 통해 이를 어느정도 해결하고자 한다.
- $f^{(l)}$: $l$번째 transformer block
- residual error: $f^{(l)}(\mathbf{x} + \mathbf{\epsilon}) - f^{(l)}(\mathbf{x})$으로 정의되는데 이를 통해 transformer block의 robustness을 측정할 수 있다. ($|| \mathbf{\epsilon} ||_2 \leq \delta$)
조금 식을 전개해보면 아래와 같은 inequality을 얻을 수 있다.

위의 inequality을 보면 Jacobian에 대한 $L_2$ norm을 추가하는 것이 최소한 locally, Lipschitz constraint을 부여하고 residual error가 bound 됨을 알 수 있다. 이러한 배경으로 본 논문에서는 jacobian에 대한 frobenius norm을 추가한다.

위의 frobenius norm은 다양한 monte-carlo estimators에 의해 approximate될 수 있는데, 본 논문에서는 hutchinson estimator을 사용한다.
Rec-denoiser의 AR estimator을 구하는 알고리즘은 아래와 같다.

Experiments
Research questions
- sota sequential recommenders에 비해서 Rec-Denoiser가 얼마나 뛰어난가?
- Rec-Denoiser는 noisy item에 얼마나 robust한가?
- 모델의 differentiable masks, jacobian regularization과 같은 부분이 Rec-Denoiser에 어떤 영향을 미치는가?
Data
- MovieLens
- Amazon
Comparing methods
- session based recommendation의 일반적인 모델: GRU4Rec, FPMC, SASRec 등
- transformer-based model: BERT4Rec, TiSASRec, SSE-PT 등
- sparse transformer-based model: Sparse Transformer, $\alpha$-entmax sparse attention
Evluation metrics
- Hit@N
- NDCG@N
Performance of Rec-Denoiser

- self-attentive sequential models이 FPMC, GRU4Rec과 같은 모델보다 성능이 뛰어나다. 즉, transformer based 모델이 long term dependencies을 잘 잡아냄을 알 수 있다.
- self-attentive model 내에서는, bi-directional attentions이나 time-intervals 등의 정보를 포함하는 BERT4Rec, Ti-SASRec과 같은 모델이 더 좋은 성능을 보인다.
- Rec-denoisers가 전체적으로 두 지표의 관점에서, 다른 방법들에 비해 우수한 성능을 보인다.
Robustness of Rec-denoisers
- 데이터의 일부를 오염시켜서 noisy data에 모델이 얼마나 robust한지 살펴보자.
- 각 데이터에 대해서 noise ratio가 높아지면 모든 모델의 성능이 떨어지는 것을 알 수 있다.
- 다만, Rec-denoisers가 다른 모델에 비해 지속적으로 높은 성능을 보임을 알 수 있다.
- 즉, noisy한 데이터에 대해 attention을 계산하는 상황에서 Rec-denoisers가 강점을 보임을 확인할 수 있다.
Study of Rec-Denoiser

- hyperparameter에 따른 모델 성능을 살펴보자. maximum lenght인 $n$이 커질수록 모델 성능은 높아진다.
- penalization parameter에 따라서 모델 성능이 상이하게 나타났다.
Conclusion
- 2022 Recsys에서 best paper 상을 받은 페이퍼를 살펴보았다. 기본적으로 implicit한 데이터에서 유의미한 아이템을 어떻게 추출할 수 있는지에 대한 고민을 masking을 통해 풀었고 이때 생기는 optimization 문제점을 테크닉적으로 풀었다.
- transformer을 추천 시스템에서 사용하는 갈래에서 attention이 가지는 근본적인 문제가 추천 시스템과 어떻게 연관되는지 알 수 있어서 흥미로운 논문이었다.
- 또한 이 페이퍼가 best paper로 선정된 것을 보니.. 역시나 추천 시스템에서는 implicit data에서 noisy 정보를 잘 걸러내는 알고리즘에 대한 고민을 하고 있음을 간접적으로 알 수 있었다.
- SASRec 등 기본적인 transformer based 논문을 읽지 않은 상태에서 해당 논문을 읽었는데, 나중에 transformer based 추천 시스템에 대해서도 서베이를 해야겠다는 생각이 들었다.