[uber/anomaly detection] Implementing Model-Agnosticism in uber's real-time Anomaly detection platform
https://www.uber.com/en-KR/blog/anomaly-detection/
Implementing Model-Agnosticism in Uber’s Real-Time Anomaly Detection Platform
Uber Engineering extended our anomaly detection platform's ability to integrate new forecast models, allowing this critical on-call service to scale to meet more complex use cases.
www.uber.com
개발 배경
기존에 uber에서는 argos라는 anomaly detection platform이 있었다. 처음에는 하나의 단일 모델을 지원했는데 각각이 다른 시간대를 가지는 새로운 모델들에 대한 니즈가 생겼다. 디자인을 새로하기보다, 기존의 플랫폼을 model-agnostic하게 만들기로 결정했다 (model-agnostic은 model에 국한되지 않는다는 뜻으로 해석된다)
Anomaly detection at Uber
2015년에 anomaly detection platform을 만들었다. 그 이후로 플랫폼은 forecasting, storage layers을 포함했다.
- forecasting layer (F3): 주기적으로 예측을 생산한다.
- storage layer: 예측 결과를 받는 곳이다.
argos에서 사용하던 알고리즘은 TimeTravel이다. 이는 30분마다 metric을 생산하는데 seasonality을 가정하는 단점이 있다. 그에 따라서 cpu 사용량 같은 정적인 metric에 대해서는 비효율적이라는 의견이 있었다. 이런 단점을 극복하기 위해, 좀 더 다양한 모델을 uber의 anomaly detection platform인 argos에 통합하기로 결졍했다.
새로운 모델 중 하나는 AutoStatic이다. 이는 24시간 예측을 수행하고 모델이 'static' threshold values을 스스로 결정하는 것에 대해 사용자들이 의지하게끔 만들어준다.
하지만 AutoStatic을 F3로 통합하기 시작하면서 F3의 아키텍쳐의 단점을 발견했다. 먼저, F3의 예측 파이프라인이 모델 메커니즘 변화를 수용할 수 없었다. 예를 들어, 다음 30분 동안 유효한 예측을 만든 모델은 다음 5시간 동안 유효한 예측을 만든 모델과 공존할 수 없었다. F3의 파이프라인은 간단히 이런 variation을 해결할 방법을 가지고 있지 않았다.
게다가 ForecastStore 이면에 있는 데이터 모델이 모든 threshold values을 저장했다. 이 threshold values는 single top-level mapping에 저장됐는데, 이는 threshold identifier에 의해서만 조회된다. 동일한 threshold에 해당하는 각기 다른 모델이 생산하는 values을 저장하기 위해 어떤 특별한 threshold key을 만들어야 했고 이는 꽤나 귀찮은 작업이었다.

그림 1을 보면 AutoStatic이나 OtherModel이 다른 이름 앞에 붙어있는 것을 알 수 있다. 이래서 key 형태로 접근하는데 불편하다는 뜻으로 보인다.
이런 단점을 극복하기 위해 F3을 TimeTravel과 분리하기로 결정한 것이다. 이런 분리 작업은 서비스가 모델에 국한되지 않고 확장성 있게끔 만들어주었다.
이를 달성하기 위해 플랫폼의 requirements을 업데이트 했다.
- Update schedules: 어떤 모델은 30분마다, 다른 모델은 24시간마다 예측한다. 이렇게 서로 다른 스케줄을 지원할 필요가 있다.
- Forecast threshold values: 모든 모델은 동일한 severity levels을 아웃풋으로 만들 필요가 있다.
이를 기반으로, 기존의 데이터 모델을 개별 모델에 의해 관리되는 'collection'의 형태로 재구성했다. 각기 다른 스케줄링을 가지는 모델은 이제 고유의 예측 유효시간을 기반으로 threshold values을 만들 수 있게 되었다.
모델에 의해서 threshold을 명시적으로 관리한다는 것은 소비자로 하여금 모델 선택 로직과 threshold 선택 로직을 분리하도록 만들어주었다. 마지막으로 이 데이터 모델은 다른 모델은 건드리지 않은 채, 만료되면 F3가 모델 예측값을 업데이트하게 해준다.
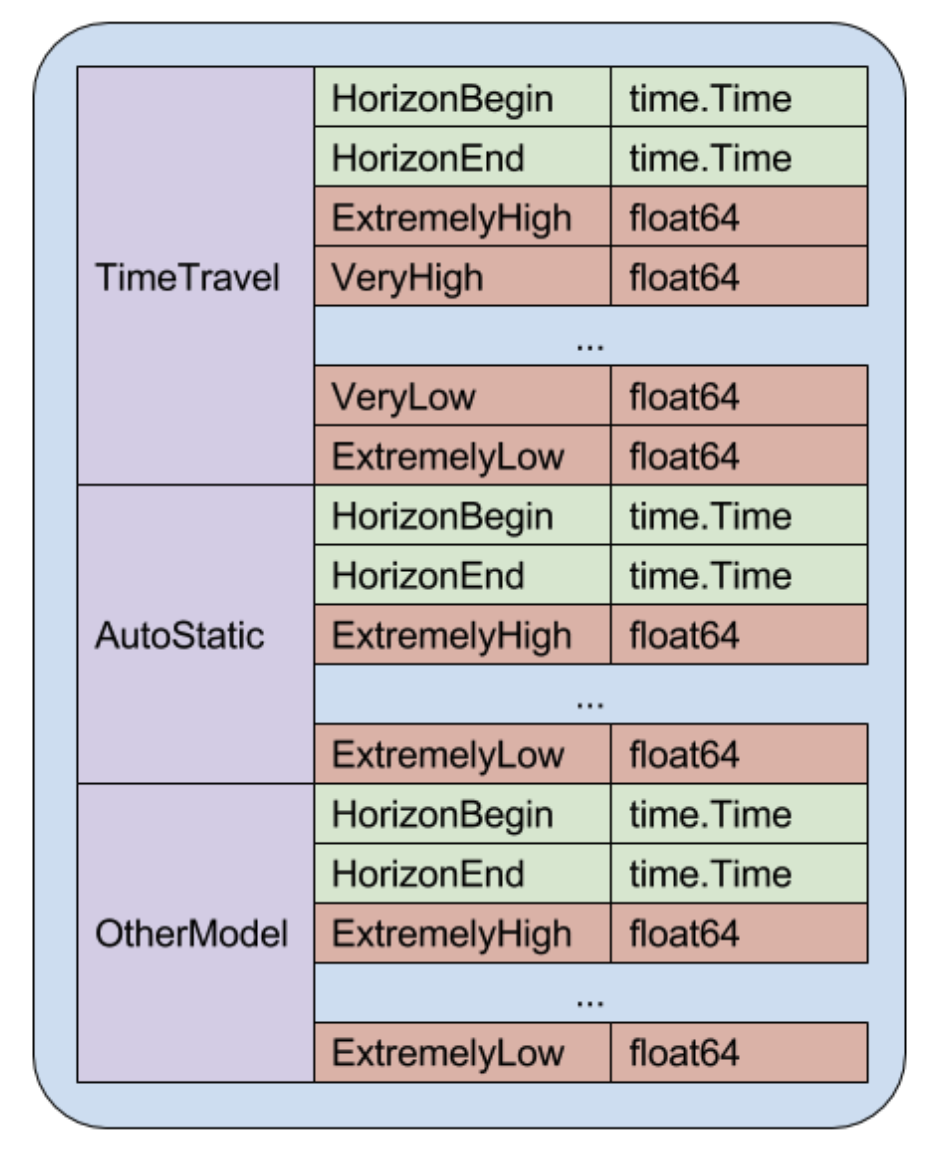
그림 1에 비해 그림 2는 모델의 이름을 앞으로 뺀 것을 확인할 수 있다. 이러한 데이터 모델에서 새로운 모델을 추가하고자할 때, model identifier symbol을 추가하기만하면 된다.
Key takeaways
- 아키텍쳐를 정적으로 보는게 아니라 외부 요구 사항에 의해 변화하고 발전하는 organic entity을 보았다는게 하나의 성과이다.
- 기존의 아키텍쳐를 갈아 엎는게 아니라 수정함으로써 작업을 완성했다는 것이 두번째 성과이다.
- 모델링 과정을 분리한 후에 이미 존재하는 production system에 통합했다는 점에서 주목을 받았다.